
How to Build a JEE Main Rank Predictor...
April 28, 2026
Home >> Python >> 10 Most Used Machine Learning Algorithms in Python

Machine learning is the concept of programming a machine so that it learns from its experiences and different examples without eing explicitly programmed. It represents an AI application where machines develop self-learning capabilities. The list of machine learning algorithms in Python combines math and logic to adapt and improve as input data evolves. Python, a general-purpose and easy-to-learn language, is widely used for various development tasks. Because it is capable of performing a variety of machine learning tasks, most algorithms are written in Python.
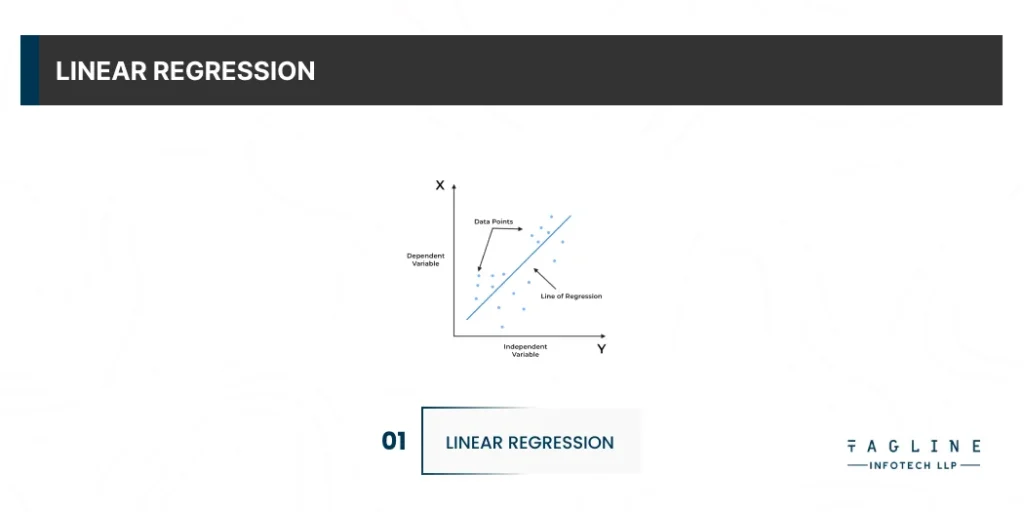
It is one of the most popular Supervised Machine Learning algorithms in Python (also called ml algorithms python) that keeps track of continuous features and predicts an outcome based on them. By fitting the best line, it establishes a relationship between dependent and independent variables.
The regression line is the best fit in the equation for providing a relationship between the dependent and independent variables. When it runs on a single variable or feature, it is referred to as simple linear regression; when it runs on multiple variables, it is referred to as multiple linear regression. Based on continuous variables, this is frequently used to estimate the cost of houses, total sales, or total number of calls.
Looking for a team of highly skilled and motivated Python developers to tackle your complex project models?
Get high-quality solutions for complex projects with our expert Python programmers . We have a proven track record of delivering exceptional results and the expertise to take on any challenge.
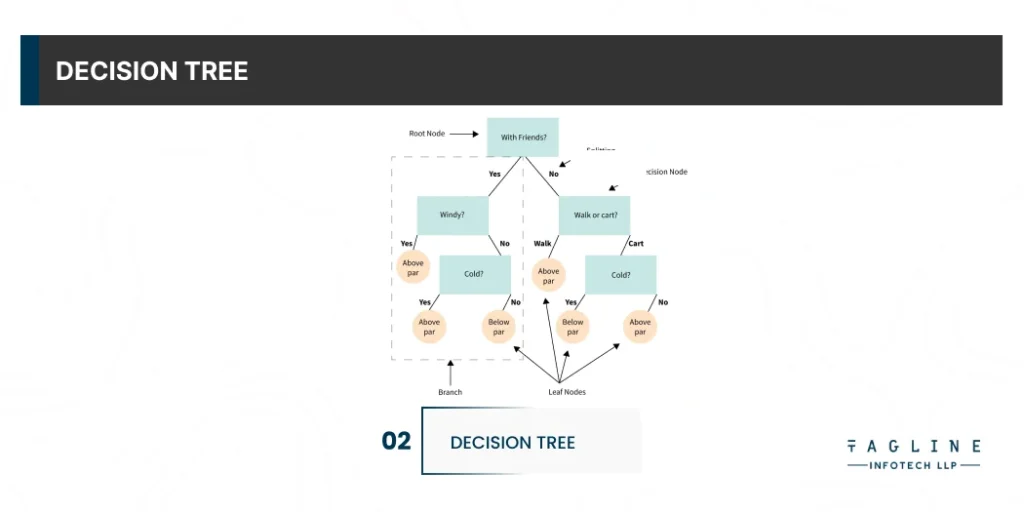
A decision tree is constructed by repeatedly asking the partition data questions. The decision tree algorithm’s goal is to improve predictiveness at each level of partitioning so that the model is always up to date with information from the dataset.
Despite the fact that it is a Supervised Machine Learning algorithm, it is primarily used for classification rather than regression. In a nutshell, the model starts with a specific instance and traverses the decision tree by comparing key features with a conditional statement. The features that are more important are closer to the root as it descends to the tree’s left or right child branch, depending on the outcome. The advantage of this machine learning algorithm is that it can be used on both continuous dependent and categorical variables.
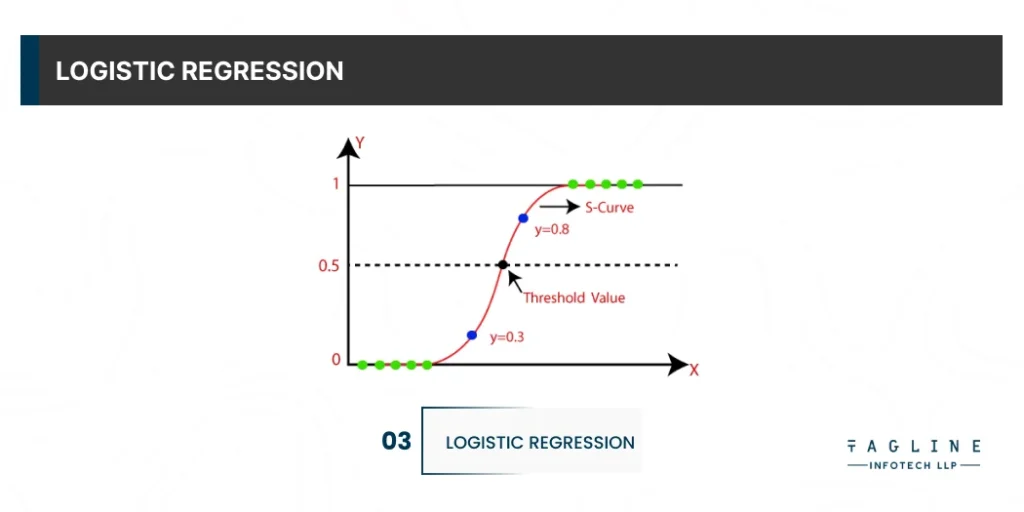
A Python supervised machine learning algorithm for estimating discrete binary values such as 0/1, yes/no, true/false. This is based on a collection of unrelated variables. This algorithm predicts the likelihood of an event occurring by fitting the data into a logistic curve or logistic function. This is why it is also referred to as logistic regression.
Logistic regression, also known as the Sigmoid function, takes any real-valued number and maps it to a value between 0 and 1. This algorithm is useful for detecting spam emails, predicting website or ad clicks, and predicting customer churn. Check out this Python Prediction project.
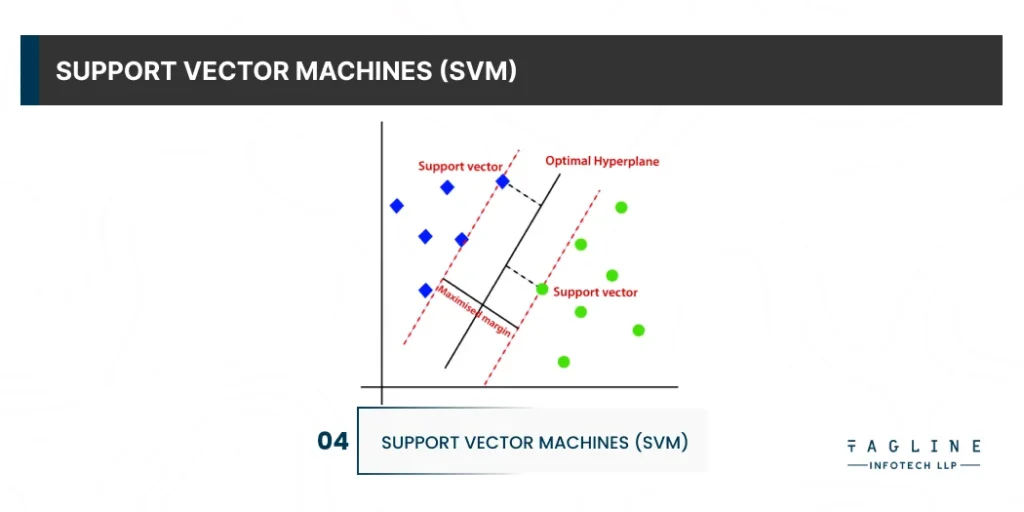
This is one of the most important machine learning algorithms in Python, primarily used for classification but also for regression tasks. Each data item is plotted as a point in n-dimensional space, where n denotes the number of features, and the value of each feature is the value of a specific coordinate.
SVM distinguishes these classes using a decision boundary. For example, if length and width are used to categorise different cells, their observations are plotted in a 2D space, and a line serves as a decision boundary. If you use three features, your decision boundary is a plane in three dimensions. When the number of dimensions exceeds the number of samples, SVM is extremely effective.
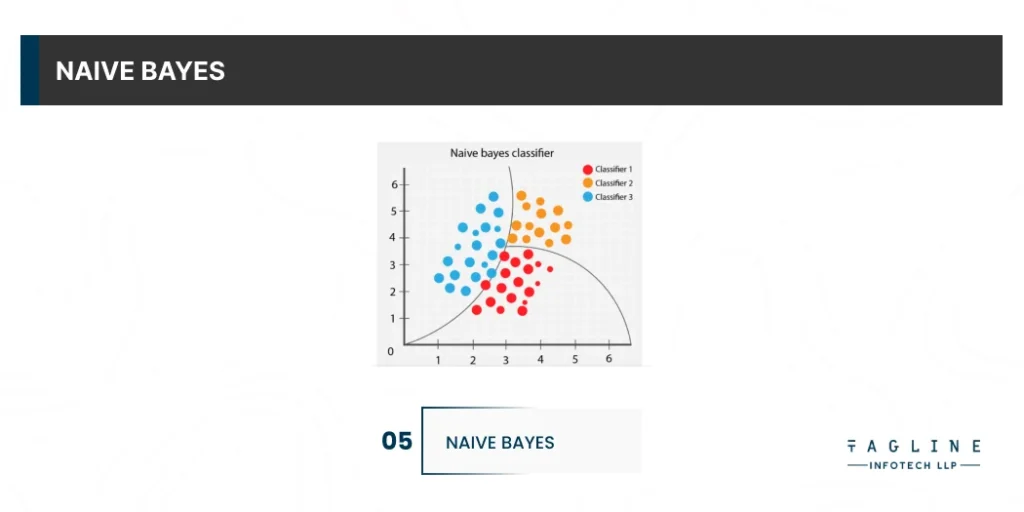
The Naive Bayes classification method is based on Bayes’ theorem. This is based on predictor independence. A Naive Bayes classifier assumes that a feature in a class is unrelated to any other feature in the class. Take a look at a fruit. If it is round, red, and 2.5 inches in diameter, it is an apple. According to a Naive Bayes classifier, these characteristics independently contribute to the likelihood of the fruit being an apple. This is true even if the features are interdependent.
A Naive Bayesian model is simple to construct for very large data sets. It is one of the most used ML algorithms in python. This model is not only simple, but it outperforms many highly sophisticated classification methods.
“12 Reasons Why Python is Good for AI and ML “
– Also Read Article
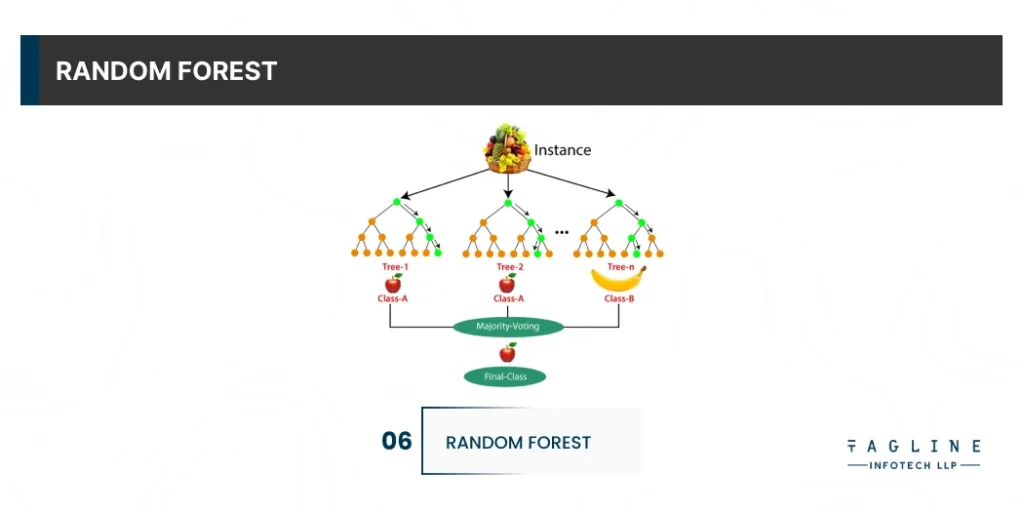
When talking about Python algorithms, the random forest algorithm establishes the outcome based on the predictions of the decision trees. It predicts by taking the average or mean of the output from various trees. Increasing the number of trees increases the precision of the outcome. A random forest eradicates the limitations of a decision tree algorithm. It reduces the overfitting of datasets and increases precision.
The K-nearest neighbours (KNN) algorithm is a supervised learning algorithm that can solve classification and regression tasks and does not fail to be in the list of ‘best ml algorithms in python’. The main idea behind this algorithm is that the data points around a data point determine its value or class.
The majority voting principle is used by the KNN classifier to determine the class of a data point. Because the model needs to store all data points, KNN becomes very slow as the number of data points increases. As a result, it is not memory efficient. Another disadvantage of KNN is that it is susceptible to outliers.
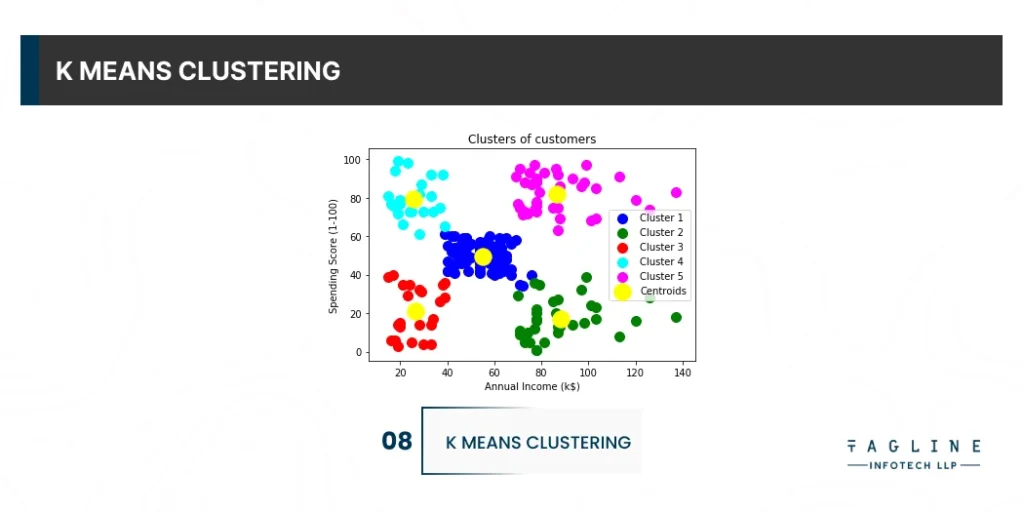
K Means Clustering is one of the most popular clustering python algorithms, and it is the first algorithm that practitioners use to get an idea of the structure of the dataset when solving clustering tasks.
It is an algorithm that will identify which data points belong to which of the k clusters given a dataset. It takes your data and learns how to group it. Through a series of iterations, the algorithm generates clusters of data points with similar variance and that minimise a specific cost function: the within-cluster sum of squares.
Ready to build powerful machine learning models in Python?
Get high-quality solutions for complex projects with Our team of experienced Developers can help you leverage the most popular algorithms to unlock the full potential of your data and achieve your business goals.
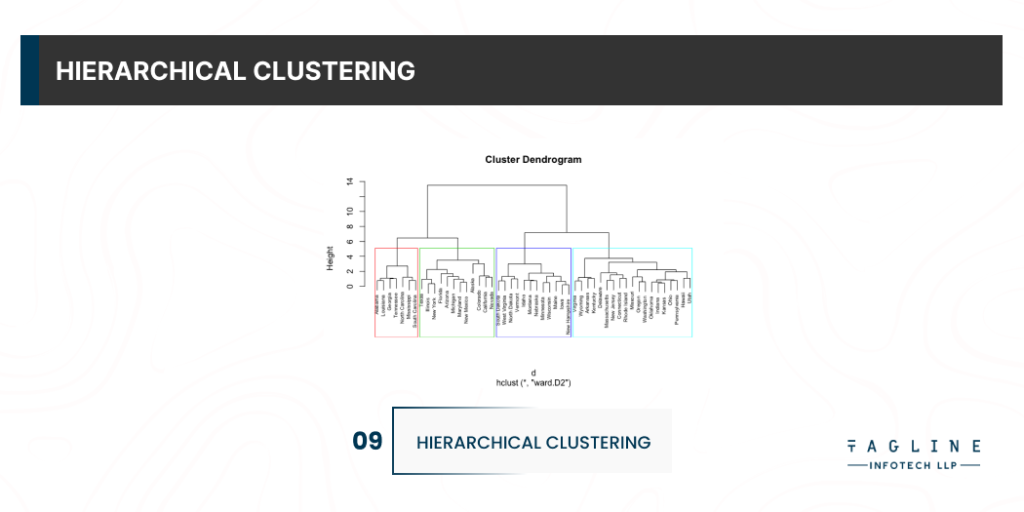
By iteratively grouping or separating data points, hierarchical clustering creates a tree of clusters. Agglomerative clustering and Divisive clustering are the two types of hierarchical clustering.
Bottom-up clustering is achieved through agglomerative clustering. It merges the two most similar points until all points are merged into a single cluster. The top-down method is divvy clustering. It begins with all data points as a single cluster and divides the least similar clusters at each step until only single data points remain. One advantage of hierarchical clustering is that the number of clusters does not have to be specified (but we can).
Neural networks are a collection of algorithms inspired by the way the human brain works. When you open your eyes, what you see is called data, and it is processed by your brain’s Neurons (data processing cells) to recognise what is around you. That is how similar the Neural Networks function.
They take a large set of data, process it (draws out patterns from the data), and output it. With CNN (Convolutional Neural Networks), RNN (Recurrent Neural Networks), Autoencoders, Deep Learning, and other variants. Neural networks are gradually becoming for data scientists and machine learning practitioners what linear regression was for statisticians. When working with regression machine learning algorithms in Python, the shift towards more complex models like neural networks reflects the evolving landscape of predictive analytics.
As a result, we discussed some important Python Machine Learning Algorithms today. Which do you believe has the most potential? Because of the high demand for technology, machine learning algorithms Python have grown in popularity in recent years. Python Development Company understands the potential for creating value from data, which is one of the main reasons it appeals to businesses across industries.
k-Means is an unsupervised algorithm that solves the clustering problem. It uses a number of clusters to classify data. The data points within a class are both homogeneous and heterogeneous in comparison to peer groups.
It is the one that maximises the margins from both tags in SVM. In other words, the hyperplane with the greatest distance to the nearest element of each tag.
April 28, 2026

February 2, 2026

January 30, 2026

October 30, 2025

September 19, 2025

Digital Valley, 423, Apple Square, beside Lajamni Chowk, Mota Varachha, Surat, Gujarat 394101
D-401, titanium city center, 100 feet anand nagar road, Ahmedabad-380015
+91 9913 808 2851133 Sampley Ln Leander, Texas, 78641
52 Godalming Avenue, wallington, London - SM6 8NW

